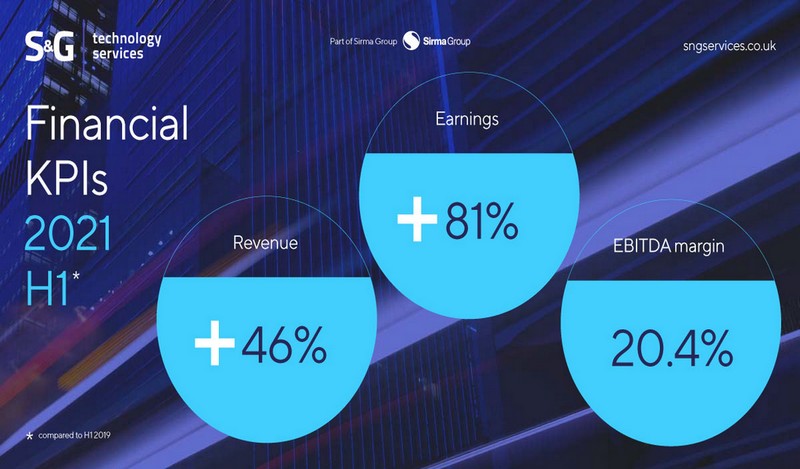
Company News / 30 Apr 2026 FY2025 Financial Results: Sirma Reports 31% Revenue Growth and Outlines Its Enterprise AI Strategy
Cross Industry News / 27 Feb 2026 Sirma Achieves IBM Gold Partner Status, Enhancing Enterprise AI, Cloud, and Automation for Clients
Company News / 27 Nov 2025 Sirma Reports 34% Growth in Sales and Prepares for Listing in Frankfurt in 2026
Public Sector News / 24 Nov 2025 Top Earning University Degrees in Bulgaria for 2025: Insights from the Higher Education Rankings
Company News / 10 Nov 2025 Sirma.AI Enterprise: A Multi-LLM Architecture for Secure, Scalable, and Smart AI Transformation
Company News / 07 Nov 2025 Sirma Expands into Dubai with AI-Driven Solutions to Empower the Region’s Business Landscape
Company News / 15 Sept 2025 Sirma Launches Proprietary AI Platform that Combines Security and Innovation
Transportation & Logistics News / 26 Aug 2025 Monika Ilieva Appointed SVP to Lead Innovation in Transportation and Logistics Vertical
Company News / 20 Aug 2025 Sirma's Commitment to ESG - Rationale and Approach to Sustainability Reporting
Company News / 07 Aug 2025 Sirma Maintains Top Positions in the Ranking of Bulgaria’s Largest Software Groups
Travel & Hospitality News / 28 Jul 2025 Darko Bosancic Appointed SVP to Lead Innovation in Travel and Hospitality
Company News / 09 May 2025 Sirma to pursue dual listing of shares on Sofia and Frankfurt stock exchanges
System Integration News / 27 Mar 2025 Sirma is an Apple Authorized Reseller for Business Organizations in Bulgaria
Data & AI News / 24 Feb 2025 Sirma Recognized as IBM Innovative Projects Partner for Watsonx™ Implementations
Cross Industry News / 12 Feb 2025 Sirma and BORICA in Partnership to Accelerate the Digitalisation of Employment Records
Company News / 17 Dec 2024 BASSCOM Barometer Presented the State of the Software Sector in Bulgaria 2024
Public Sector News / 29 Oct 2024 Bulgarian University Rankings 2024: A Comprehensive Guide to Higher Education Success
Company News / 23 Oct 2024 Sirma Group Expands into Romanian Market with Acquisition of Roweb Development
InsurTech News / 02 Oct 2024 Galina Koleva Appointed SVP of Insurance: Strategic Move for Sirma Insurance Vertical
Company News / 18 Sept 2024 Shareholders of Sirma Group Holding Give Green Light of Corporate Consolidation
Company News / 21 Jun 2024 Sirma Group Holding To Acquire the Majority Stake in Romanian IT company Roweb
Packaging & Measurement News / 18 Jun 2024 EngView Systems Presents its Latest Packaging Software at Drupa 2024
Packaging & Measurement News / 28 May 2024 EngView Systems Showcases the Latest Technologies in the Packaging Software at Drupa
FinTech News / 26 Apr 2024 Technology and Banking communities in Bulgaria are at the Forefront of Innovations
ESG News / 02 Feb 2024 Double Materiality in Action: Sirma's Data Center Leading the Way in Sustainability
Company News / 04 Jan 2024 Sirma Takes Strides Towards a Greener Future with an In-House Photovoltaic System
Company News / 04 Oct 2023 Sirma Solutions Showcases its Brand and Job Opportunities at Career Show 2023
Company News / 30 Aug 2023 Sirma Group Holds the Leading Position in Revenues Among Bulgarian Software Companies
Company News / 13 Sept 2022 TBI Info Became Sirma InsurTech to Accelerate the Digitalization of Insurance Enterprises
Company News / 27 May 2022 Integral Venture Partners Acquires 76 Percent of the Leading Semantic Provider Ontotext
Company News / 09 May 2022 Sirma Venture Lab Offers up to €400K Investment in Top-performing Startups
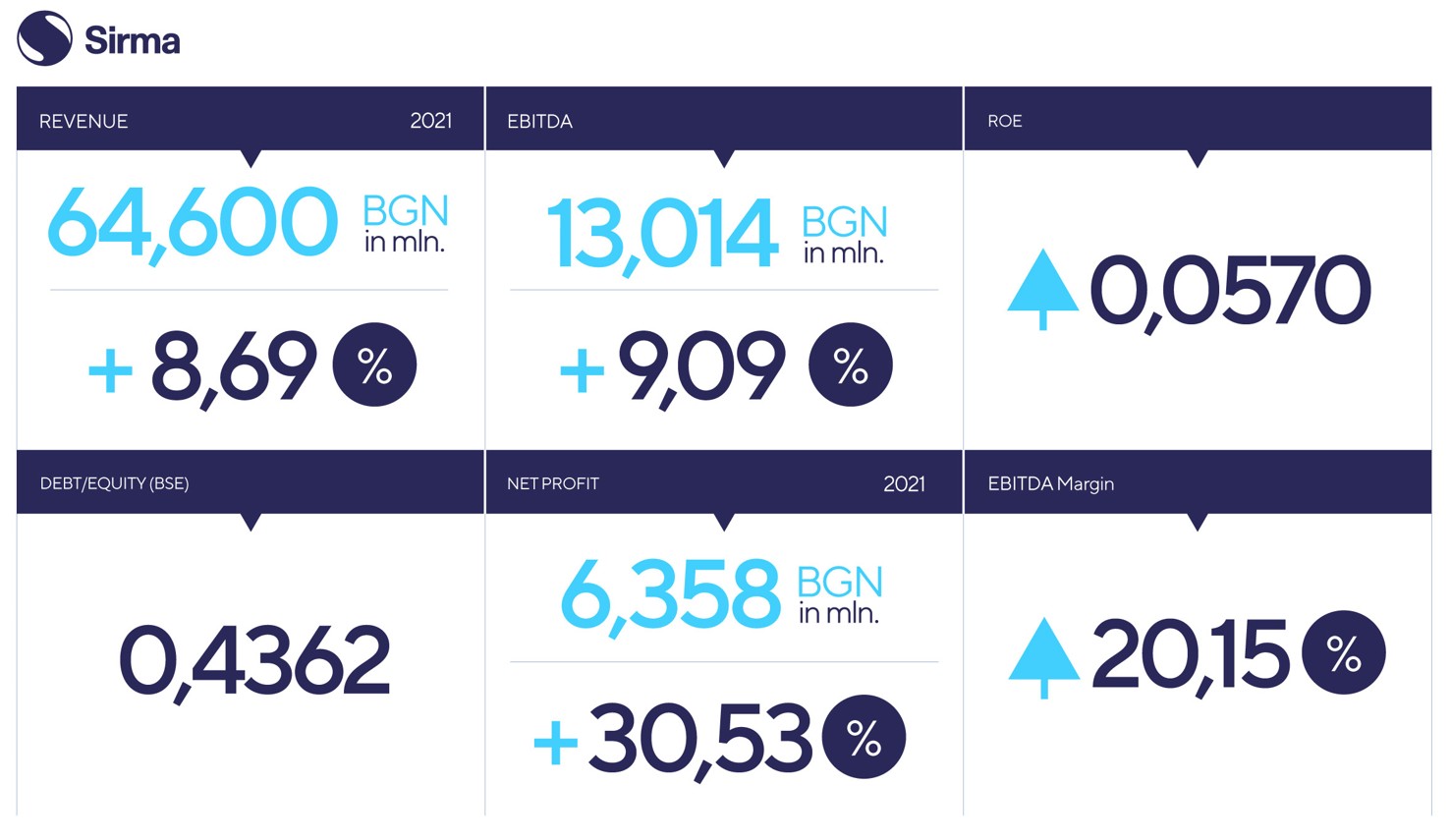
Company News / 02 Mar 2022 Sirma Group Holding Disclosed its Interim Consolidated Results as at 31.12.2021
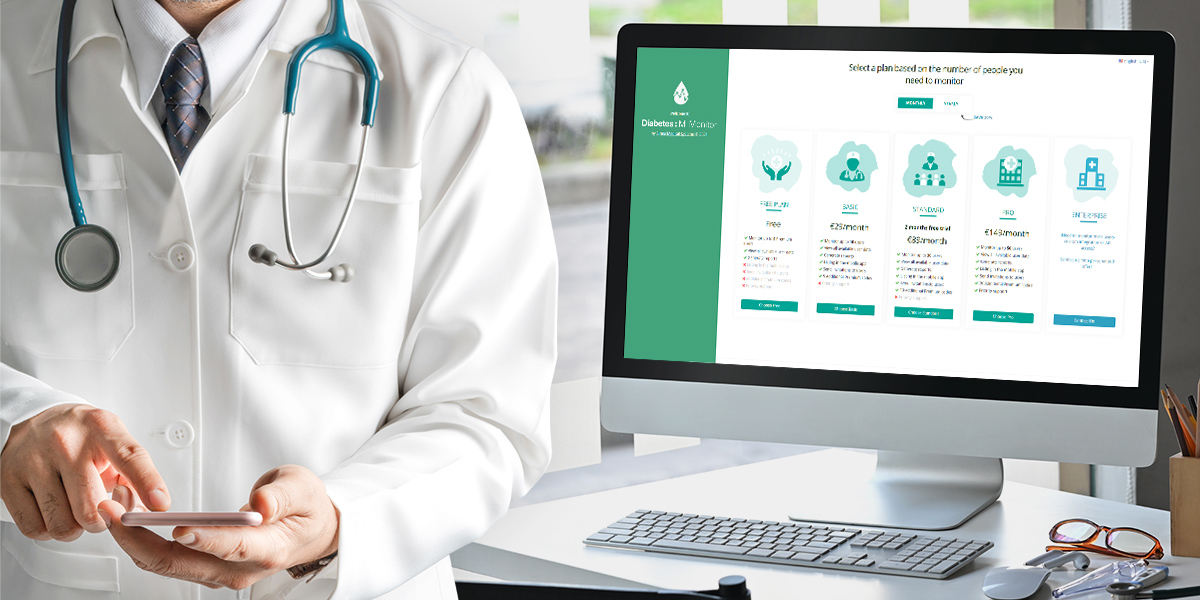
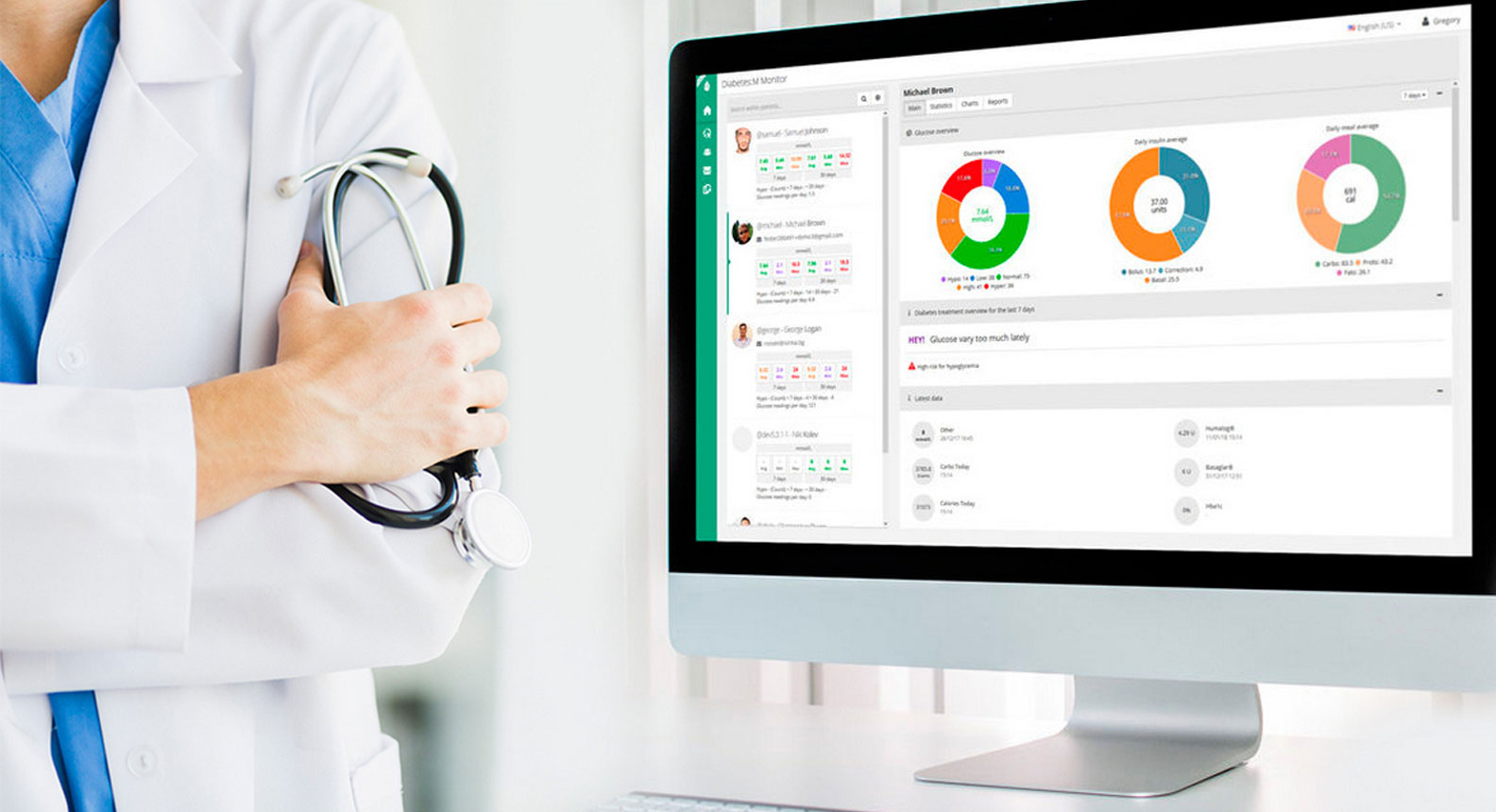
Healthcare News / 28 Feb 2022 Diabetes: M Medical Advisory Board to Accelerate Innovation in Digital Healthcare Products
Company News / 17 Feb 2022 The Mobile World Congress 2022 in Barcelona Brings Together the Digital Community
Company News / 16 Nov 2021 Sirma Group Holding Acquires Sciant Unlocking the Potential for Synergy and Growth
FinTech News / 08 Sept 2021 Sirma is Showing off Melinda at the Biggest FinTech Event Money 20/20 in Amsterdam
Cross Industry News / 14 Jul 2021 Ontotext Platform 3.5 with many deployment and operational improvements
Cloud Migration and Support News / 01 Jun 2021 Daticum and CLICO Bulgaria collaborate to provide top-notch cybersecurity solutions
Packaging & Measurement News / 27 Apr 2021 EngView Package & Display Designer Now Available as Subscription Plans
Retail News / 04 Dec 2020 Notos Bulgaria and Sirma collaborate to implement unified commerce platform
Cross Industry News / 19 Nov 2020 GraphDB selected by Johnson Controls for the New Release of Metasys Building Automation System
Healthcare News / 21 Jul 2020 New Medrec:M version is now available with a handful of exciting features
Company News / 16 Jul 2020 Sirma Group among the best companies in Top 100 ICT ranking in Bulgaria for 2019
Cross Industry News / 17 Jun 2020 Ontotext and Semantic Web Company shake hands to accelerate Enterprise Knowledge Graphs
Healthcare News / 07 May 2020 Sofia Municipality featured Medrec:M among innovative digital services for its citizens
Healthcare News / 07 Apr 2020 Sirma's CEO Tsvetan Alexiev Announcement About the Future of Telemedicine and Medrec:M
Healthcare News / 06 Apr 2020 Sirma Announces the Release of Its Free Mobile App Medrec:M – Personal Medical Record of the Future
Packaging & Measurement News / 26 Mar 2020 Free Home-office Licenses for EngView Customers During the COVID-19 Outbreak
FinTech News / 02 Mar 2020 Sirma's Open Banking Suite to Fuel the Development of New PSD2 Compliant Payment Products
FinTech News / 26 Feb 2020 The Development of Fintech Ecosystem in Bulgaria Requires a Change in Mindset
Company News / 01 Oct 2019 GraphDB 9.0 Offers New Functionalities to Empower Knowledge Graph Solutions
Packaging & Measurement News / 16 May 2019 EngView Systems Launches 7.0 Version of its Packaging Suite